With the inclusion of PR 15795, the Theia 1.63.0 release that has been built today now supports Ollama release 0.9.0 which has introduced several improvements, which are now also available in Theia AI. This post highlights those improvements and gives a few general hints on how to improve your experience with Ollama in Theia AI.
Streaming Tool Calling
One of the most interesting features of the Ollama 0.9.0 release is support for streaming tool calling in the API. This makes working with the LLM much more convenient, as you can follow the output and tool calls during the generation. As a side effect, this also boosts output quality especially for tool calls for the models that support them. See this article for more information on this.
Starting with Theia 1.63.0, Theia AI uses the new streaming API including tool calling so that Ollama models now behave more like models from other providers, such as OpenAI, Google, and Anthropic.
Explicit Thinking Markup
Thinking or reasoning in LLMs have received much attention in the recent months, especially since deepseek-r1 was announced. While Ollama did support reasoning models for several months now, the reasoning steps have always been part of the actually generated response and could only be extracted by looking for <think>...</think> or similar markup generated by the LLM.
Ollama 0.9.0 has added support for distinguishing reasoning output and actual output on the API level. The new Ollama provider in Theia propagates this feature so collapsible reasoning blocks are rendered on the UI level.
Token Usage Reporting for Ollama
Of course, as you are running Ollama most likely on your own hardware, the token usage report is not as crucial as with paid third-party services. But still, it might be at least interesting to know how many tokens you are using with your own Ollama server.
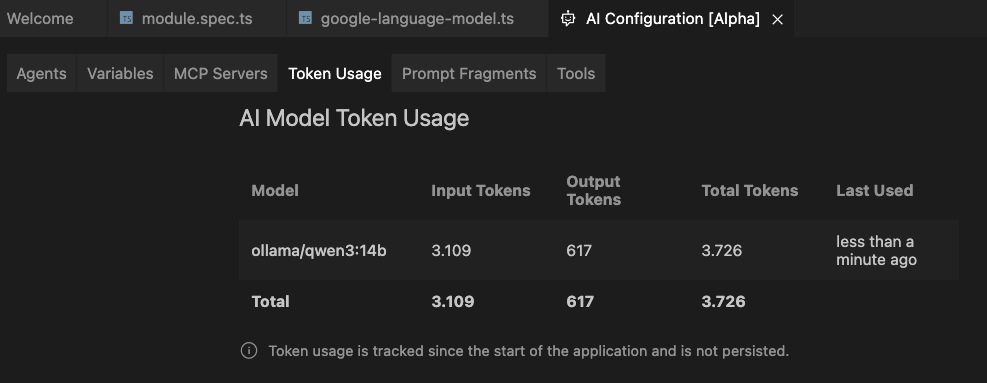
The new Ollama provider released in Theia 1.63.0 now reports token usage statistics in the AI Configuration View in the tab Token Usage.
Support for Images in the Chat Context
Theia 1.63.0 has added preliminary support for images in the Theia AI chat. Using the + button in the AI Chat, it is now possible to add images which are passed to the LLM as part of the context. This is also supported for Ollama LLMs; but note that not many models support images. One example is the llava model.
If unsure, you can use the ollama show command in a terminal to check for the image capability of a model.
Configuration and Usage Hints
Using an Ollama server running on usually limited local hardware is most likely no competition for paid 3rd party services. But maybe the absence of token limits and privacy concerns are still sometimes more important than performance. To make Ollama models at least a bit more usable in practice, it is important to tweak the configuration to adapt it to your hardware and needs. This section gives some hints about possible optimizations. Note: these settings have been tested with an Apple Silicon M1 Max system; for other hardware, please refer to other blog articles that discuss Ollama optimizations.
Ollama Server Settings
To reduce the memory footprint of the request context, set these environment variables before executing ollama serve:
-
OLLAMA_FLASH_ATTENTION=1 -
OLLAMA_KV_CACHE_TYPE="q8_0"
See the Ollama FAQ for more details.
Theia AI Considerations
We might be tempted to download and use different models for different Theia AI agents, e.g. a universal model, such as qwen3 for universal tasks, and more specialized models, such as codellama for code-centric tasks like the Coder or Code Completion agent. However, we need to consider that each model that is loaded at the same time uses a lot of memory so that Ollama might decide to unload models that are not used at the moment. And since unloading and loading models takes some time, performance decreases if you use too many models.
Therefore, it is usually a better idea to use fewer models, for example one smaller model for tasks that should not take too long (such as Code Completion and Chat Session Naming), and one larger model for complex tasks (such as Architect or Coder agents). The best results can be achieved if both models fit in the available VRAM so that no model loading/unloading occurs.
Theia AI Request Settings
One important thing to note is that Ollama per default uses a context window of just 2048 tokens. Most tasks in Theia AI will not provide satisfactory results with this default. Therefore it is important to adjust the request settings and to increase the num_ctx parameter. As with the model size discussed before, the context size should be set to match the agent and task because a larger context leads to results with higher quality but longer runtimes. Therefore, it is important to play around with the settings and find the optimal settings matching the used models and the use case.
These hints provide some initial help:
- Check the Ollama server logs and keep an eye out for messages like this:
"truncating input prompt" limit=2048 prompt=4313 keep=4 new=1024
This message indicates that the input prompt exceeds the required context length, so the input prompt will be truncated (which will usually lead to bad answers from the model, as it will forget half of the question you were asking...) - Also during the process of loading a model, if you see a message like
llama_context: n_ctx_per_seq (2048) < n_ctx_train (40960)
this indicates that the current num_ctx (2048) setting is smaller than the context window the model was trained with (40960).
Alternatively, you can also useollama showto check for the context length property of the model. (Do not confuse the context length property, which is the theoretical maximum context length for this model with the num_ctx parameter, which is the actual context length used in requests).
To adjust the num_ctx parameter in Theia, go to Settings > AI Features > Model Settings and follow the link to open the settings.json file in the editor.
Then create a new setting like this:
"ai-features.modelSettings.requestSettings": [
{
"scope": {
"agentId": "Coder",
"modelId": "ollama/qwen3:14b",
"providerId": "ollama"
},
"requestSettings": { "num_ctx": 40960 }
}]
In the scope part, you declare the provider, model, and agent to which apply the settings. You can leave out either key to apply the setting for all providers, agents, and/or models, respectively.
In the same way you can adjust and play around with the other Ollama parameters, such as temperature, top_k, etc.